



封面新闻记者 欧阳宏宇
近期,IEEE海外诡计机视觉与模式识别会议( Conference on Computer Vision and Pattern Recognition)CVPR 2025公布论文委派截至,其中一项来自中国的将AI应用于酬酢限度平台案例筹商论文《Teller: Real-Time Streaming Audio-Driven Portrait Animation with Autoregressive Motion Generation》(《基于自回来作为生成的及时流式音频运行东说念主像动画系统》)被接受。
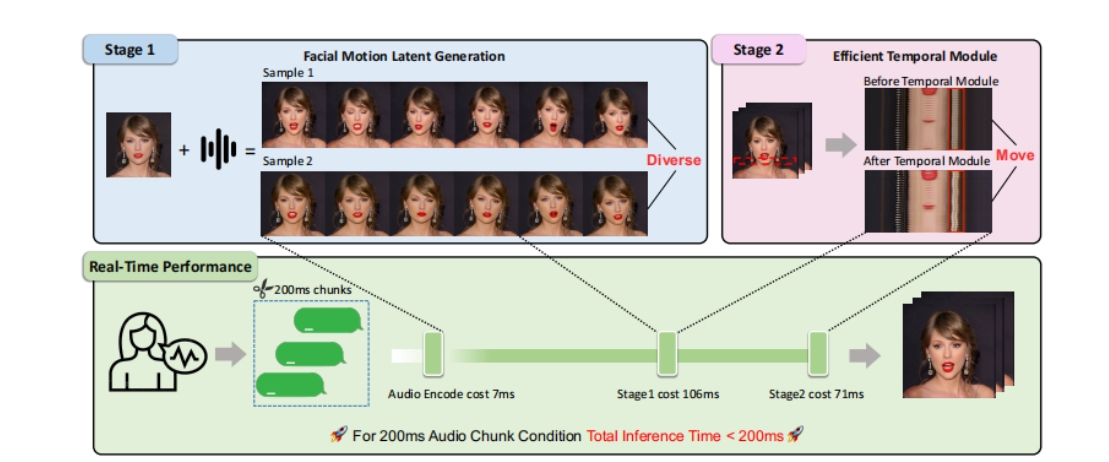
据先容,筹商团队在论文中提议了一个新的面向及时音频运行东说念主像动画(即Talking Head)的自回来框架,处分了视频画面生成耗时长的行业挑战外,还达成了话语时头部生成以及东说念主体各部位畅通的当然性和传神性。
该论文的动机是解构diffusion-base的模子要道规律,用LLM和1step-diffusion进行重构,和会视频模态,使SoulX大模子成为同期生成笔墨、语音、视频的Unified Model。
具体而言,来自Soul App的筹商团队将talking head任务分红FMLG(面部Motion生成)、ETM(高效身体Movement生成)模块。FMLG基于自回来语言模子,哄骗大模子的雄壮学习才智和高效的各样性采样才智,生成准确且各样的面部Motion。ETM则哄骗一步扩散,生成传神的身体肌肉、饰品的畅通效果。
履行截至标明,比拟扩散模子,该决策的视频生告成率大幅进步,且从生成质地上来看,轻微作为、面部身体作为合作度、当然度方面均有优异阐发。这证明了国产酬酢限度互联网技能在鼓舞多模态才智构建格外是视觉层面才智禁锢上得到了阶段性后果。
谈及筹商团队所存眷的视觉交互逻辑,该平台CTO陶明解释称,从交互的信息复杂度来讲,东说念主和东说念主濒临面的调换是信息传播形态最快的,亦然最有用的一种。“是以咱们觉得在线上东说念主机交互的流程当中,需要有这么的抒发形态。”
在他看来,在多模态大模子才智观点基础上,该决策的提议将有助于AI构建及时生成的“数字寰球”,何况约略以灵活的数字形象与用户进行当然的交互。
公开尊府浮现,CVPR是东说念主工智能限度最具学术影响力的顶级会议之一,是中国诡计机学会(CCF)保举的A类海外学术会议。在谷歌学术方针2024年列出的内行最有影响力的科学期刊/会议中,CVPR位列总榜第2,仅次于Nature。凭证会议官方统计,本次CVPR 2025会议总投稿13008篇,委派2878篇开云kaiyun,委派率仅为22.1%。